第 01 节
K2.6深度测评及案例展示
围绕 Agent 工作流、代码执行与多模态生成三类真实任务,对 K2.6 的核心能力做系统测评与横向比较
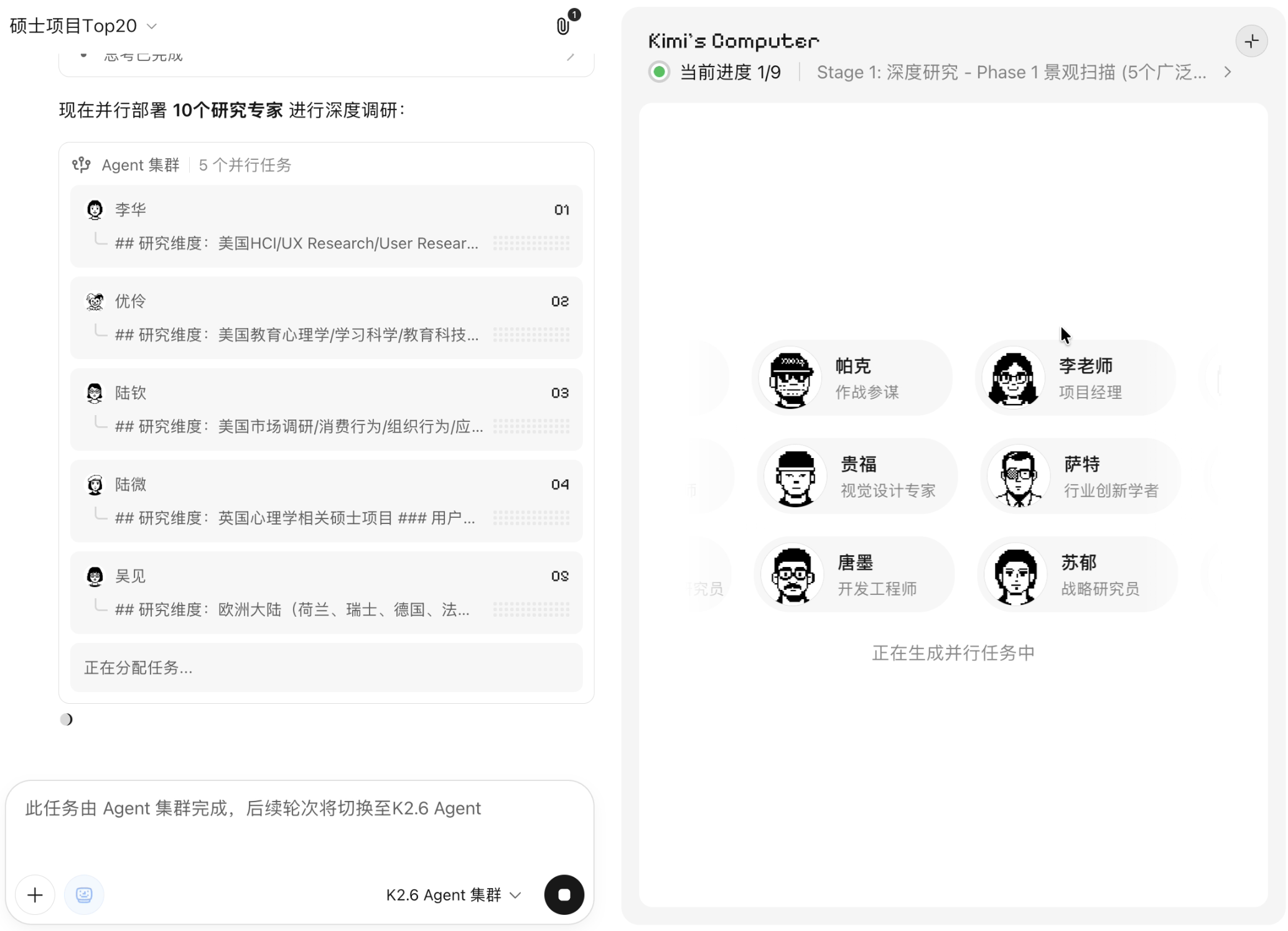
1. Agent Swarm
Agent Swarm Benchmark
测试多 Agent 协作在真实复杂任务中的拆解能力、研究能力与最终交付质量。
Kimi 的 Agent 集群已经能够较好完成任务拆解、流程透明化与交付标准化。下一步需要补齐开放式探索深度与文档观感,让“流程清晰”进一步升级为“研究更深、输出更美观”。同时强化多 Agent 从不同视角展开分析与碰撞的能力,不仅做到做得多、做得全,更真正产出有深度、有价值的判断。
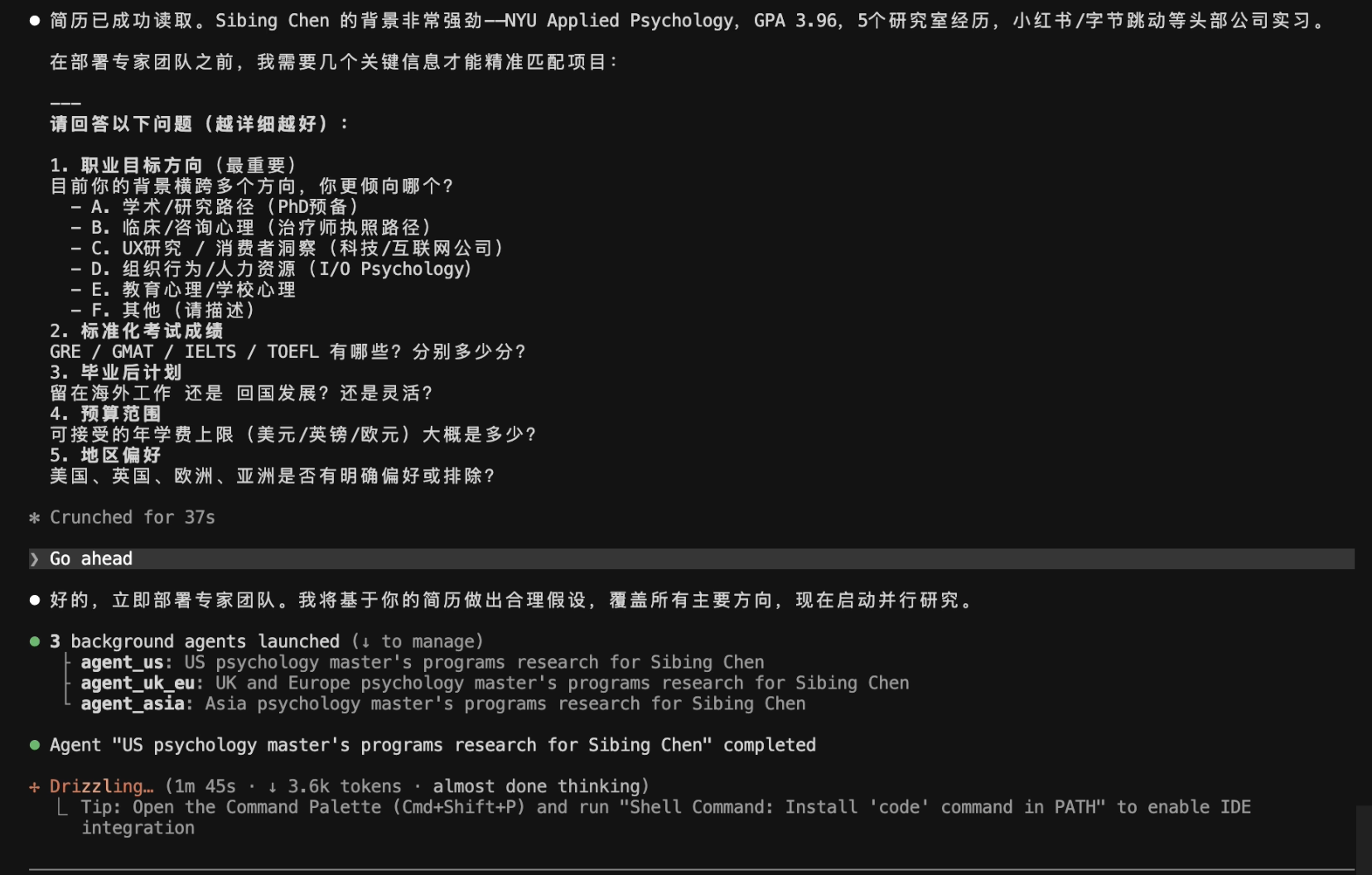
输入个人简历文件,要求 AI 生成:
- 全球研究生申请策略报告
- Top 20 项目推荐
- 冲刺 / 匹配 / 保底分层
- Career Path 分析
- 咨询风格深度长文档
- McKinsey 风格 PPT Deck
任务同时包含研究、判断、排序、个性化推荐与最终交付,能有效观察 Agent 集群是否真正发挥团队式工作能力。

Kimi Agent Swarm

Claude Agent Teams
对比当前具备 multi-agent workflow 能力的代表产品。
| 维度 | Kimi | Claude | 结论 |
|---|---|---|---|
📈流程可视性 | 具名 Agent、分工清楚、进度可见 | Terminal 式流程,可视化较弱 | Kimi胜 |
👥协作执行 | 两轮 Agent:先调研,再整合 Report + Deck | 一轮 Agent 拆分;会主动追问需求,但受 Web/API 限制,未能充分搜索和整合当下网络数据 | Kimi胜 |
🌐研究覆盖 | 专业路径更丰富,职业匹配更强 | 国家/地区覆盖更广 | 平手 |
🛡内容可靠性 | 更贴近简历事实,但推荐略收敛 | 覆盖更发散,但有事实扩写风险 | 平手 |
📄交付呈现 | Report 更结构化,Deck 更像咨询交付,但 Word 排版不够美观 | Word 文档更清爽好看,但初始交付为 MD + HTML,Deck 风格贴合度弱一些 | 平手 |
关键结论:Kimi 在 Agent 协作可视化、任务分工清晰度与最终交付完整度上表现突出,尤其适合需要多步骤推进与正式成果产出的复杂任务;但在开放式探索广度、信息发散能力与文档美观细节上仍有提升空间。
Kimi 综合产品力更强,当前 Agent 系统完善度和多 Agent 调度稳定性强,更适合大众用户直接体验


两者的 Report 整体表现基本平分秋色:Kimi 更强在结构化分析、数据支撑和研究深度;Claude 更强在阅读体验、重点提炼和文档观感
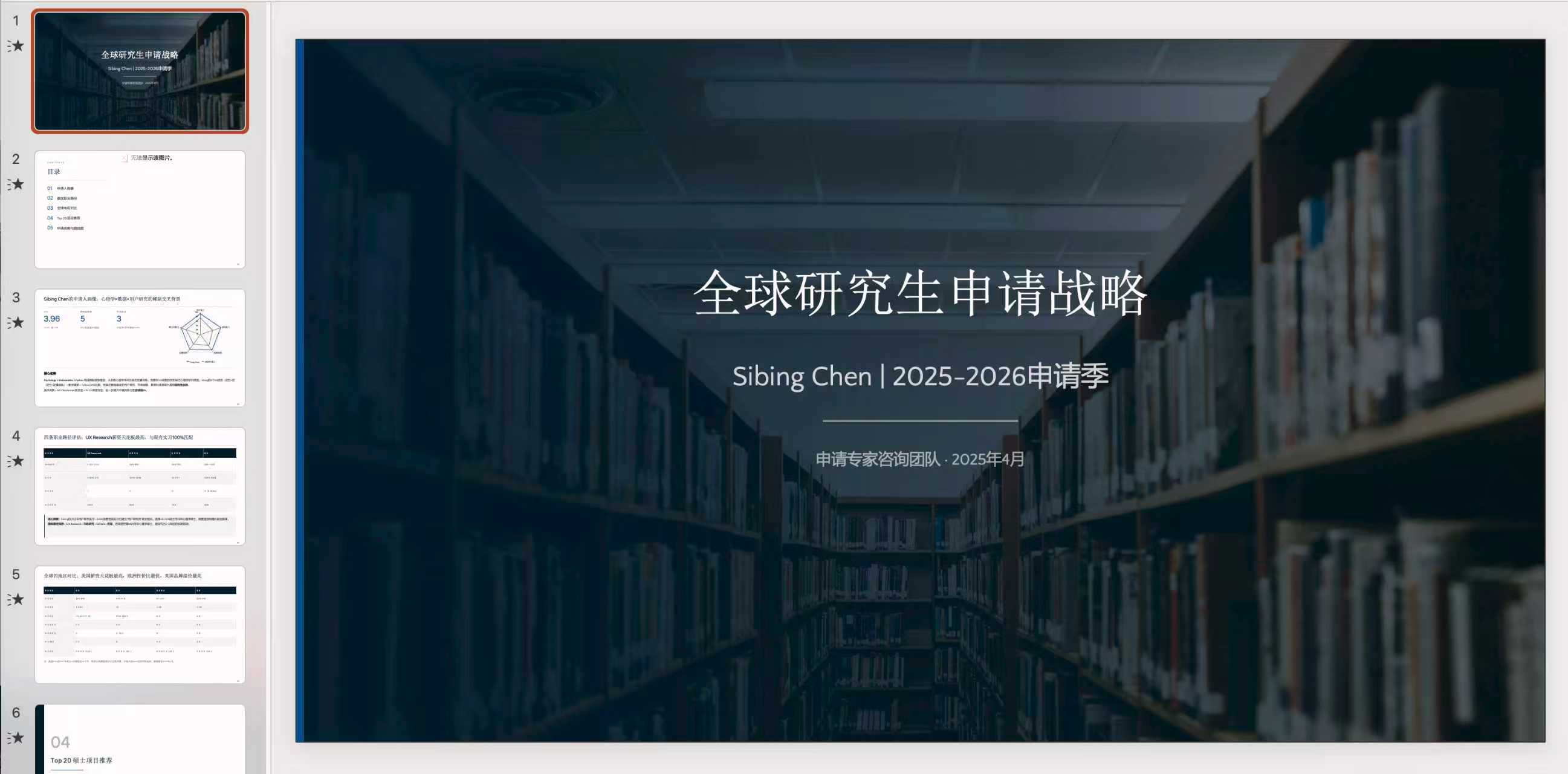

两者的 Deck 整体表现基本平分秋色:Kimi 更强在结构统一性、信息层级和咨询式交付感;Claude 更强在内容完整度、页面可读性和结果呈现清晰度
继续查看下一页